
플랫폼 팀의 Temporal 사용기: 입금 계류 및 반환 작업 편

들어가며
지난 글 입출금 운영 자동화 시스템 Chronos 개발기 (feat. Temporal)에서 코빗 블록체인 테크 팀이 Temporal로 입출금 운영을 자동화한 사례를 소개했습니다.
이번에는 플랫폼 팀의 이야기입니다. 코빗 플랫폼 팀은 입금 처리 과정 전반에 Temporal을 도입해, 외부 솔루션 연동부터 입금 계류 및 반환까지의 흐름을 안정적으로 관리하고 있습니다. 이 글에서는 입금 처리의 어떤 특성이 Temporal과 잘 맞았는지, 그리고 도입 후 무엇이 달라졌는지를 이야기합니다.
코인 거래소 입금 처리의 특성
코인 거래소의 입금 처리는 단순히 "잔고에 반영"하는 일이 아닙니다. 블록체인에서 입금이 감지된 후 여러 단계를 거쳐야 비로소 고객 잔고에 반영됩니다.
대표적인 흐름을 보면:
- 블록체인에서 입금 감지
- 외부 AML 솔루션(Chainalysis 등)으로 스크리닝 — 입금 출처가 안전한지 검사
- 스크리닝 결과에 따라 잔고 반영 또는 계류
- 계류된 건 중 반환 대상이 확정되면 자산 이동 → 블록체인 출금 → 완료 처리
이 과정에서 세 가지 특성이 개발을 어렵게 만듭니다.
외부 시스템 의존이 많습니다. 자금세탁방지(AML)와 이상거래감시(FDS)를 위한 솔루션들, 블록체인 네트워크, 내부 자산 관리 시스템 등 여러 시스템과 연동해야 합니다. 그런데 각 시스템의 응답 시점을 예측할 수 없습니다.
비동기 구간이 길고 불확실합니다. 스크리닝 결과가 1초 만에 나올 수도 있고, 수십 초가 걸릴 수도 있습니다. 블록체인 출금 확인도 마찬가지입니다. 언제 끝날지 모르는 작업을 안전하게 기다려야 합니다.
중간 실패가 허용되지 않습니다. 자산 이동은 끝났는데 출금에서 실패하면 롤백해야 합니다. 스크리닝이 끝나지 않은 상태에서 잔고에 반영되면 안 됩니다. 어떤 단계에서 장애가 나더라도 정합성이 깨져서는 안 됩니다.
기존 방식의 한계
이런 문제를 풀기 위해 저희도 처음에는 익숙한 방법을 사용했습니다.
- 일시적 오류에는 재시도 로직을 두고
- 상태 테이블에 각 단계의 진행 상황을 기록하고
- 미완료 건은 배치 작업으로 다시 처리하고
- 실패하면 보상 트랜잭션으로 정합성을 맞추는 방식이었습니다.
Batch Job은 저희 팀에게 가장 익숙한 방법이었고, 단기간에 도입하기 쉬운 선택지였습니다.
하지만 입금 처리 구간이 늘어나고 외부 연동이 복잡해질수록 한계가 드러났습니다. 재시도 로직이 코드 곳곳에 흩어지고, 장애가 발생하면 로그와 상태 테이블을 뒤져 작업이 어디까지 진행됐는지 추적해야 했습니다. 모니터링을 위해 Slack 연동까지 별도로 구축해야 했고, 시간이 흐를수록 비즈니스 로직보다 실패 처리 코드가 더 많아지는 구조가 됐습니다.
왜 Temporal인가
Temporal을 선택한 이유는 입금 처리의 특성과 정확히 맞아떨어졌기 때문입니다.
완료 시점을 예측할 수 없는 작업을 안정적으로 처리합니다. 스크리닝 결과 대기든 블록체인 출금 확인이든, Workflow에서 durable timer(Workflow.sleep)를 사용해 polling 패턴으로 구현할 수 있고, 네트워크 오류 같은 인프라 실패에 대한 재시도는 Retry Policy로 분리해 관리할 수 있습니다.
워크플로우별 모니터링 대시보드를 제공합니다. 현재 단계, 실패 사유, 재시도 현황, 이벤트 히스토리를 실시간으로 확인할 수 있습니다.
워크플로우 단위로 관리되어 재시도가 안전합니다. 중복 실행을 구조적으로 차단하고, 워크플로우 상태와 이력이 Temporal에 유지되기 때문에 Worker나 서버 장애 이후에도 중단 지점부터 이어서 처리할 수 있습니다.
물론 Temporal도 클러스터 운영 부담이 있습니다. 저희는 사내에 이미 Temporal 클러스터가 구축되어 있었고 다른 팀에서도 활용하고 있었기 때문에 인프라 측면의 추가 비용은 크지 않았습니다. 클러스터가 없는 상황이라면 이 부분도 함께 고려해야 합니다.
계류 반환 흐름과 Temporal
아래 코드는 실제 구현을 블로그용으로 단순화한 것입니다. 핵심 구조와 패턴은 동일하지만, 일부 타입과 세부 로직은 생략했습니다.
반환 작업은 초기화 → 자산 이동 → 출금 요청 → 출금 확인 → 완료의 흐름을 거칩니다. 출금이 실패하면 자산을 원래 상태로 되돌려야 합니다.
@ActivityInterface
interface RefundActivity {
fun initRefund(refund: Refund)
fun transferAsset(refund: Refund)
fun requestWithdrawal(refund: Refund)
fun confirmRefund(refund: Refund): RefundConfirmStatus // PENDING / SUCCESS / FAILED
fun complete(refund: Refund)
fun failedProcessBack(refund: Refund) // 출금 실패 시 보상 처리
}confirmRefund가 단순 Boolean이 아니라 3-state enum을 반환하는 점이 중요합니다. "아직 모른다(PENDING)", "성공했다(SUCCESS)", "실패했다(FAILED)"를 구분해야 하기 때문입니다.
override fun processRefund(refund: Refund): RefundResult {
activities.initRefund(refund)
activities.transferAsset(refund)
activities.requestWithdrawal(refund)
// 출금 결과가 확정될 때까지 10초 간격으로 polling
val confirmStatus = pollUntilConfirmFinal {
activities.confirmRefund(refund)
}
if (confirmStatus == RefundConfirmStatus.FAILED) {
activities.failedProcessBack(refund) // 자산을 원래 상태로 롤백
throw ApplicationFailure.newFailure(
"withdrawal failed (holdingId=${refund.holdingId})",
"RefundWithdrawalFailed"
)
}
activities.complete(refund)
return RefundResult.success(refund.holdingId)
}pollUntilConfirmFinal은 PENDING이면 Workflow.sleep()(durable timer)으로 대기한 뒤 다시 확인하고, SUCCESS나 FAILED가 나오면 루프를 빠져나옵니다. 여기서 polling과 Activity retry는 별개의 메커니즘입니다. polling은 비즈니스 조건을 반복 확인하는 워크플로우 레벨의 로직이고, Activity retry는 네트워크 오류 같은 인프라 실패에 대한 자동 재시도입니다.
출금이 실패하면 failedProcessBack으로 보상 처리를 합니다. 이 보상 로직이 워크플로우의 한 단계로 자연스럽게 표현됩니다. 기존 방식이었다면 별도의 보상 트랜잭션 관리 코드, 상태 테이블 업데이트, 실패 시 재시도 로직을 따로 작성해야 했을 것입니다.
실전에서는 모든 액티비티에 같은 재시도 정책을 적용하기보다, 각 액티비티의 실패 특성에 맞게 다르게 설정하는 것이 중요합니다. 반환 워크플로우에서도 Activity별로 재시도 정책을 다르게 설정하고 있으며, 입금 스크리닝 구간에서도 같은 패턴을 적용해 한 구간에서 검증한 설계를 다른 구간에 그대로 재활용할 수 있었습니다.
실패에서 복구하기
Temporal이 장애 상황을 어떻게 다루는지, 반환 워크플로우를 기준으로 두 가지 사례를 보겠습니다.
네트워크 이슈로 액티비티가 실패한 경우
자산 이동 단계에서 네트워크 이슈가 발생한 상황입니다.
processRefund()
├─ initRefund() → 완료
├─ transferAsset() → 네트워크 오류로 실패
└─ Temporal이 Retry Policy에 따라 자동 재시도앞서 설정한 Retry Policy(maxAttempts=3, maxInterval=1분)에 따라 Temporal이 자동으로 재시도합니다. 개발자가 재시도 로직을 직접 작성할 필요가 없습니다.
출금 확인 중 버그가 발생한 경우
블록체인 출금까지 끝났지만, confirmRefund 로직의 버그로 무한 대기에 빠진 상황입니다.
processRefund()
├─ initRefund() → 완료
├─ transferAsset() → 완료
├─ requestWithdrawal() → 완료
├─ confirmRefund() → 버그로 무한 대기
└─ Workflow는 아직 실행 중이미 자산 이동과 출금이 끝난 상태이므로 처음부터 다시 실행할 수는 없습니다. 하지만 버그를 수정해 재배포하면, Temporal의 Replay 메커니즘으로 복구할 수 있습니다.
Replay의 동작 방식
Temporal은 워크플로우의 각 Activity 결과를 Event History에 저장합니다. Worker가 재시작되면 이 히스토리를 읽어 워크플로우 코드를 처음부터 다시 실행하되, 이미 완료된 Activity는 저장된 결과를 그대로 사용합니다.
Step 1: initRefund() → replay (저장된 결과 사용)
Step 2: transferAsset() → replay (저장된 결과 사용)
Step 3: requestWithdrawal() → replay (저장된 결과 사용)
Step 4: confirmRefund() → 수정된 코드로 실제 실행이미 끝난 단계를 다시 실행하지 않으므로, 자산이 이중으로 이동하거나 출금이 중복 요청되는 일이 없습니다. 버그가 있던 confirmRefund만 새 코드로 실행됩니다.
다만 워크플로우가 이미 종료된 뒤 Reset이나 Re-run을 하는 경우에는 Activity가 다시 실행될 수 있습니다. 그래서 Activity는 반드시 멱등하게 설계해야 합니다.
참고로, polling 대신 Signal을 사용하면 외부 이벤트가 발생했을 때 워크플로우를 즉시 다음 단계로 진행시킬 수도 있습니다. 시스템 구성에 따라 polling이 더 유연할 때도 있고, Signal이 더 적합할 때도 있습니다.
도입 후 달라진 것
코드 구조
대부분의 재시도와 상태 추적 책임이 Temporal의 Retry Policy와 Event History 중심으로 정리되면서, 코드 리뷰에서 비즈니스 로직에 대한 논의 비중이 높아졌습니다. 실패 시 보상 처리조차 워크플로우의 한 단계로 표현되면서, 별도의 보상 트랜잭션 관리 코드가 필요 없어졌습니다.
모니터링
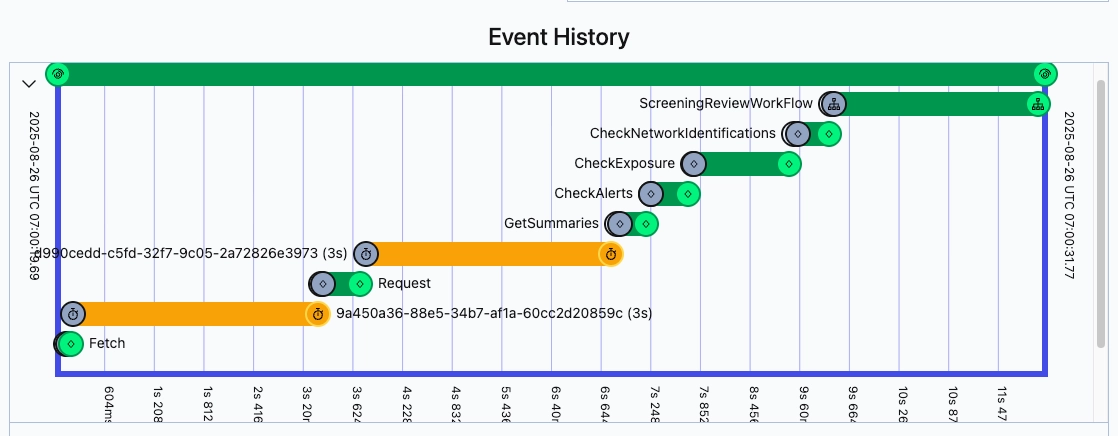
Temporal 대시보드에서 워크플로우가 어느 Activity에서 얼마나 시간을 쓰는지 건별로 확인할 수 있습니다. 장애 발생 시 "어디까지 진행됐는지" 확인하는 과정이 대시보드에서 워크플로우 이력을 조회하는 것으로 단순해졌습니다.
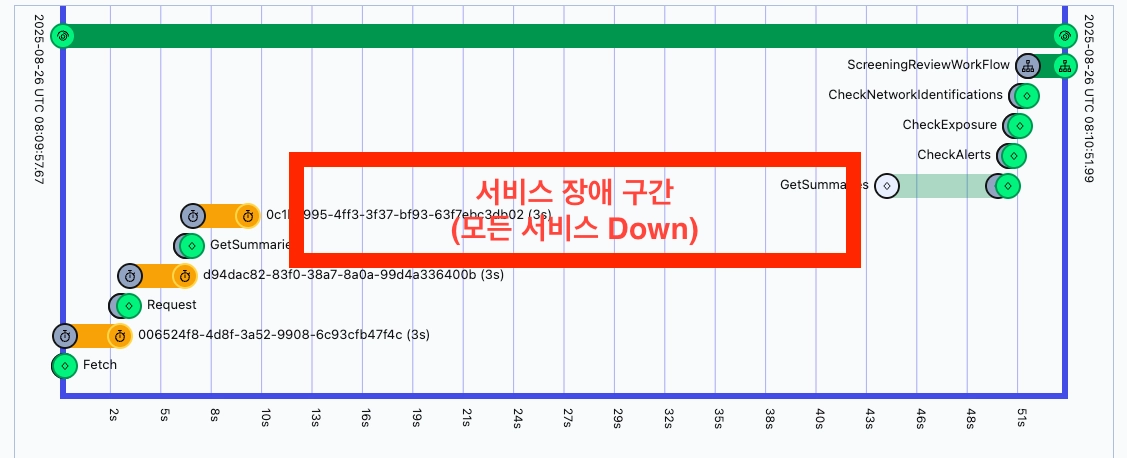
서비스 장애가 발생해 워크플로우가 중단되는 경우에는 복구 후 대시보드에서 어떤 건이 어디서 멈췄고 어디서부터 재시도됐는지를 바로 확인할 수 있었습니다. 이전이었다면 로그를 뒤지고 DB 상태를 대조하며 한참을 추적해야 했을 일입니다.
운영
장기간 실행되는 상위 워크플로우에서는 Workflow.continueAsNew()로 Event History를 주기적으로 초기화하고, 워크플로우 ID 기반 중복 방지(ALLOW_DUPLICATE_FAILED_ONLY)로 같은 건이 중복 처리되지 않도록 관리하고 있습니다. 앞서 언급한 멱등성 원칙을 기반으로, Temporal이 재시도하더라도 결과가 달라지지 않도록 했습니다.
맺으며
입금 처리는 겉으로 보면 단순한 절차처럼 보이지만, 실제 운영 환경에서는 실패와 재시작, 복구와 추적이 끊임없이 따릅니다. 중요한 것은 기능을 한 번 구현하는 일이 아니라, 그 기능을 실패 속에서도 끝까지 안전하게 완료할 수 있는 구조로 만드는 일이었습니다.
정리하면, 코인 거래소 입출금은 외부 블록체인 네트워크나 AML 시스템에 의존하는 구간이 많고, 처리 완료 시점을 예측할 수 없으며, 중간 실패가 허용되지 않습니다. 이런 특성이 Temporal의 durable execution 모델과 잘 맞았습니다.
그리고 앞으로 더 많은 입출금 프로세스를 대상으로 Temporal 적용을 확장해 나갈 계획입니다. 이 사례가 긴 흐름을 안정적으로 운영해야 하는 문제를 고민하는 분들께 도움이 되었으면 합니다.